(1) Introduction to Causal Inference
Causal Data Science for Business Analytics
Monday, 24. June 2024
Map of Causality
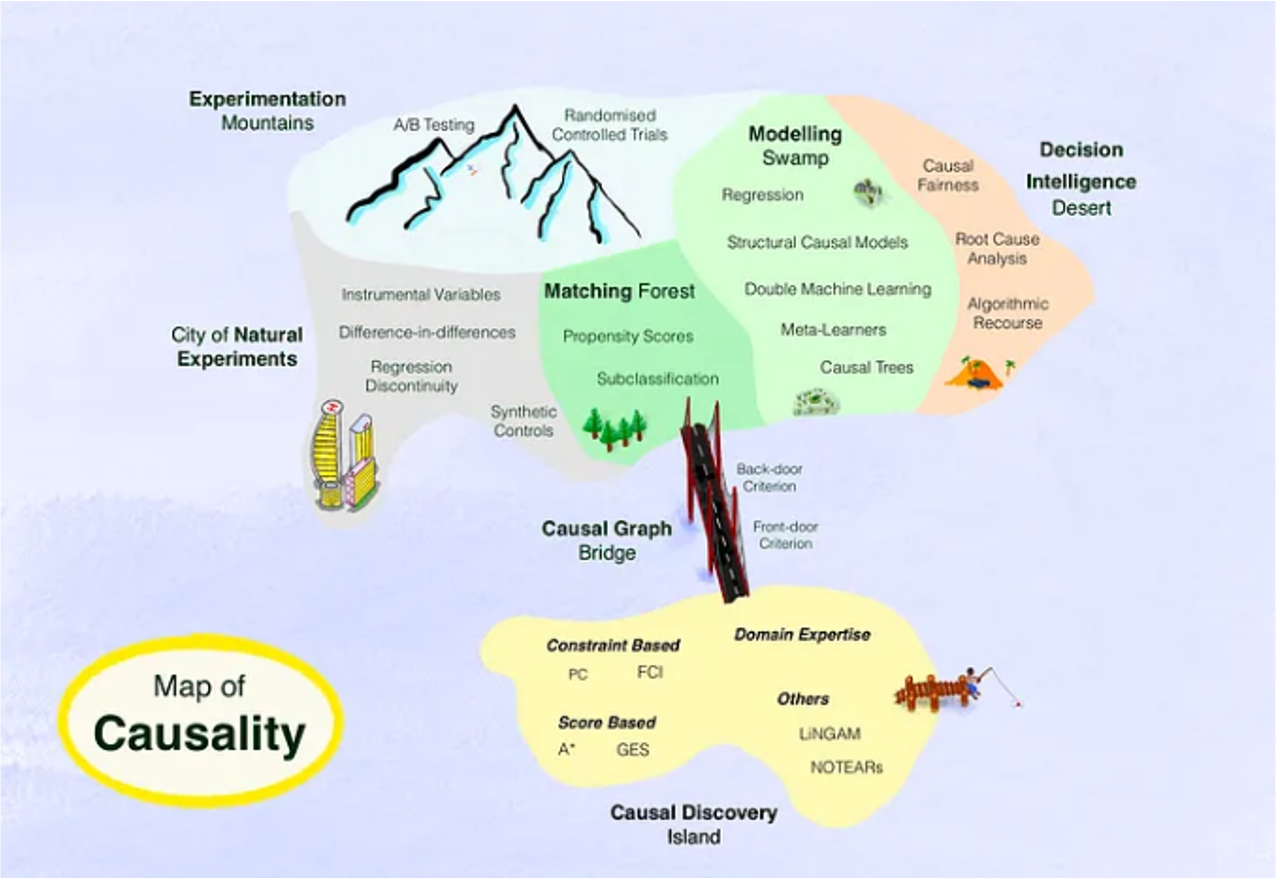
Source: https://towardsdatascience.com (2023).
Causality vs. Correlation
- “Correlation does not imply causation.”
- “You can not prove causality with statistics.”
- But statistics is crucial for understanding causality:
- Formal language for causal inference.
- Methods to estimate causal effects.

Causality vs. Correlation

Causality vs. Correlation
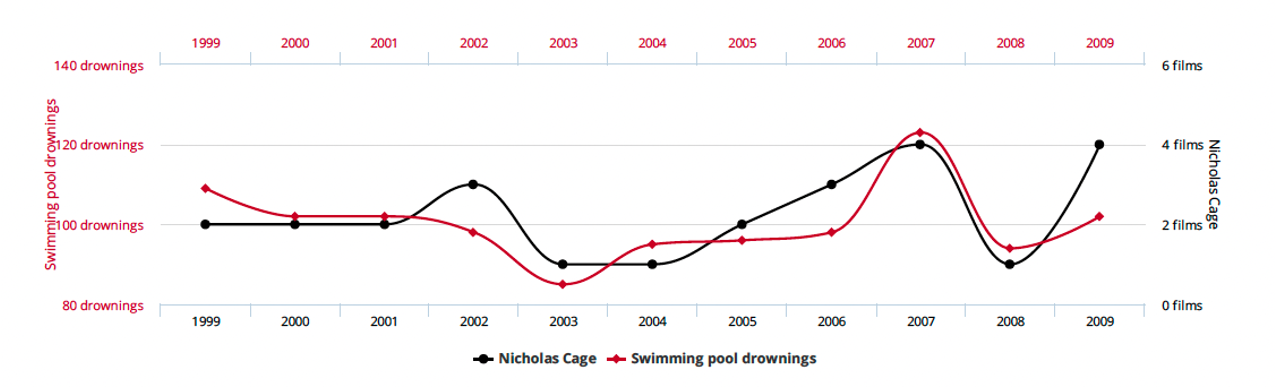
Causality vs. Correlation
Source: Peters, Jonas. 2015. Causality: Lecture Notes, ETH Zurich.
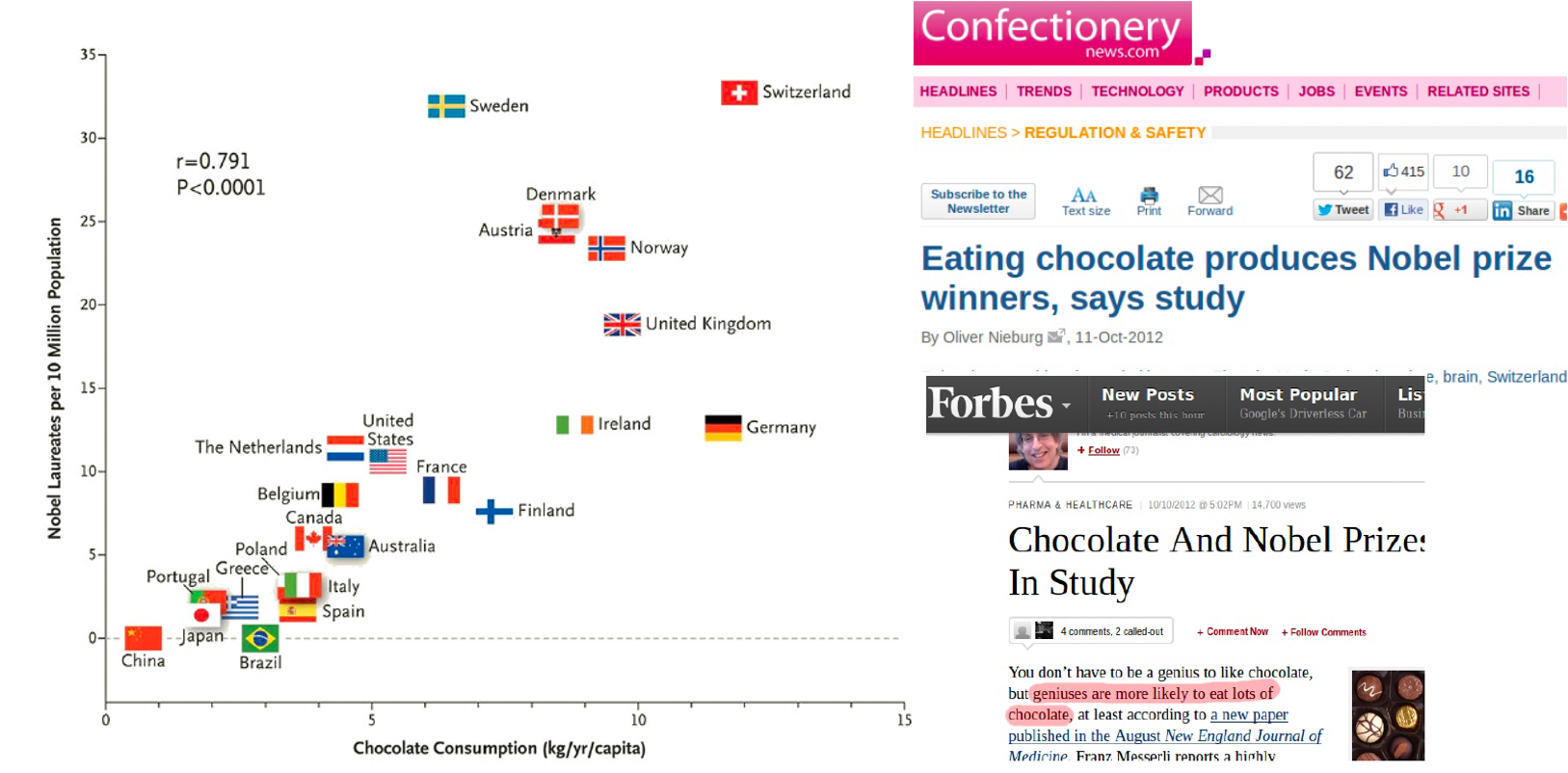
Causality vs. Correlation
- Correlation, or better association, is not (entirely) causation, if there is confounding association due to a common cause, i.e. a confounder.
- E.g. drinking the night before is a common cause of sleeping with shoes on and of waking up with a headache:
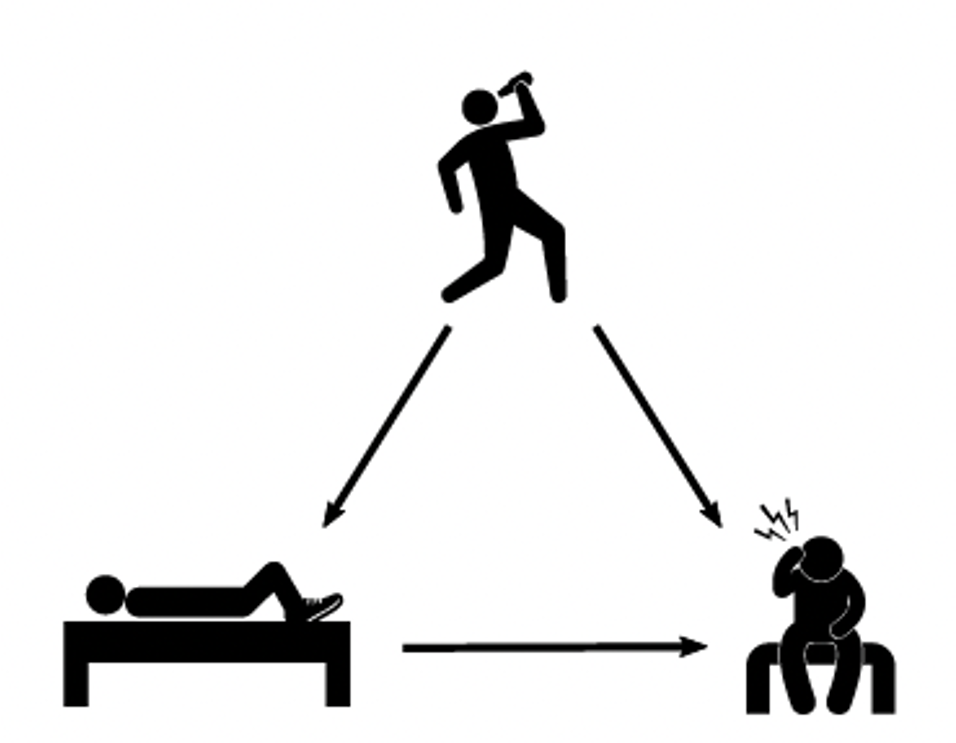
Source: Neal, Brady (2020). Introduction to causal inference from a Machine Learning Perspective. Course Lecture Notes (draft).
Causality vs. Correlation
- Correlation, or better association, is not (entirely) causation, if there is confounding association due to a common cause, i.e. a confounder.
- E.g. Consumers’ purchase intent is a common cause of the amount spent on search engine marketing (SEM) (esp. for branded vs. non-branded ads) and sales (especially for frequent consumers):
Show code
library(ggdag)
library(ggplot2)
coord_dag <- list(
x = c(SEM = 0, Intent = 1, Sales = 2),
y = c(SEM = 0, Intent = 1, Sales = 0)
)
dag <- ggdag::dagify(SEM ~ Intent,
Sales ~ SEM,
Sales ~ Intent,
coords = coord_dag)
dag %>%
ggplot(aes(x = x, y = y, xend = xend, yend = yend)) +
geom_dag_point(colour = "grey") +
geom_dag_edges() +
geom_dag_text(colour = "black", size = 5) +
theme_dag(legend.position = "none")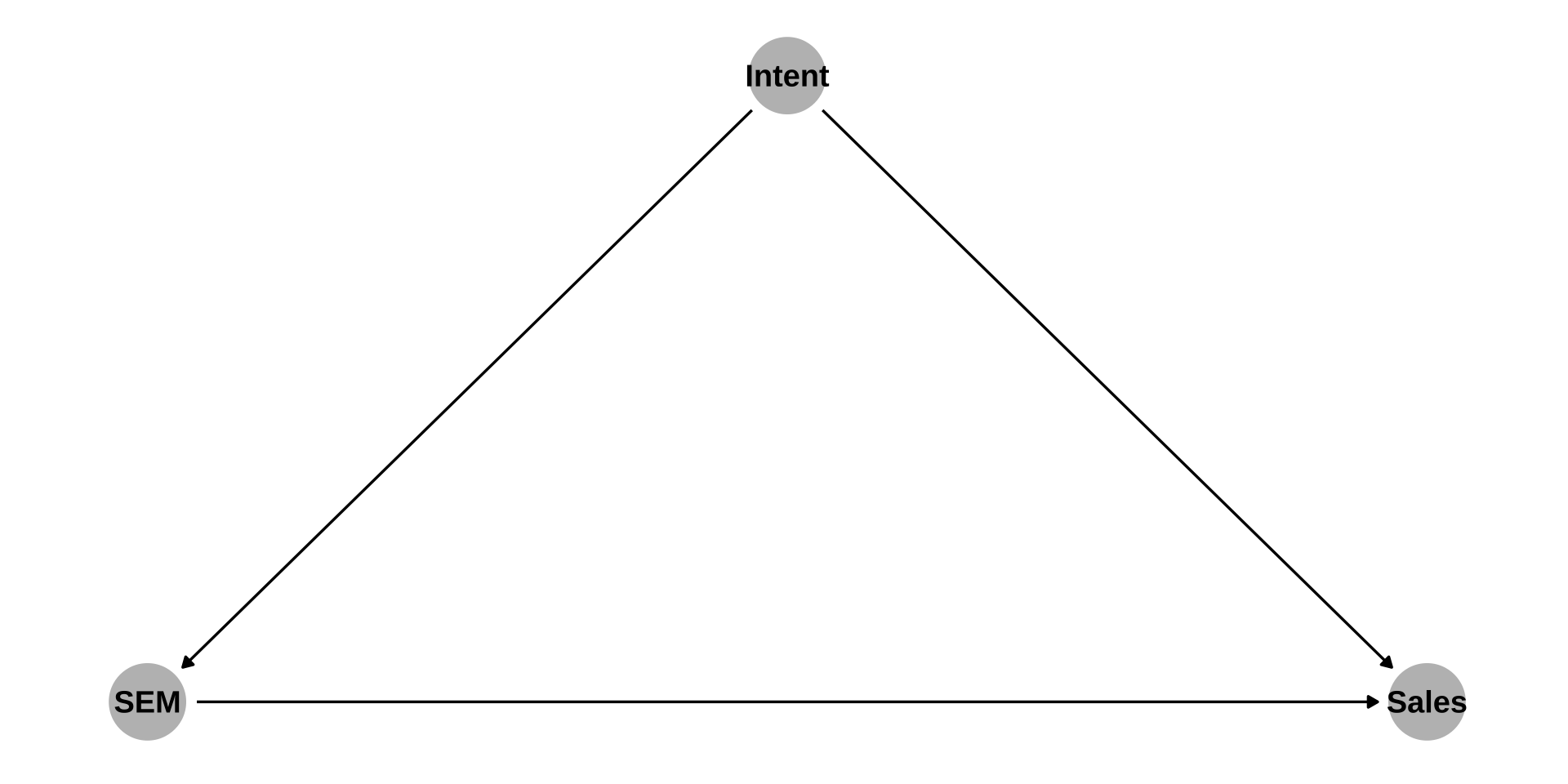
Motivating Example: Gender Pay Gap (4)
Show code
data <- data.frame(
Salary = c(5319.82, 3015.18, 5592.44, 3163.30, 3960.08, 3479.09),
Position = c("Management", "Non-Management", "Management", "Non-Management", "All Positions", "All Positions"),
Gender = c("Male", "Male", "Female", "Female", "Male", "Female")
)
library(ggplot2)
data |>
ggplot(aes(x=Gender, y=Salary, group=Position, colour=Position)) +
geom_line() + geom_point() +
theme_bw()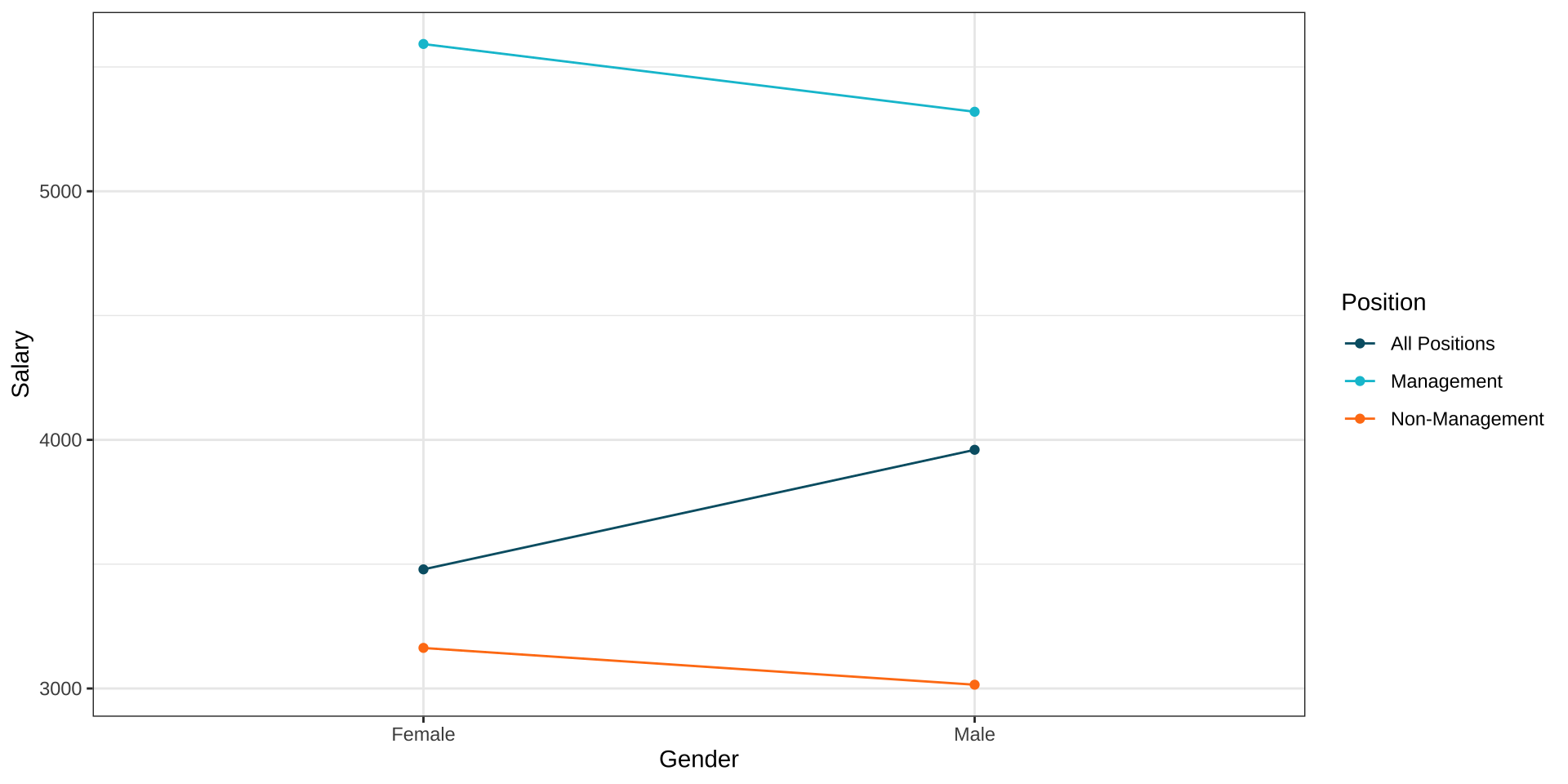
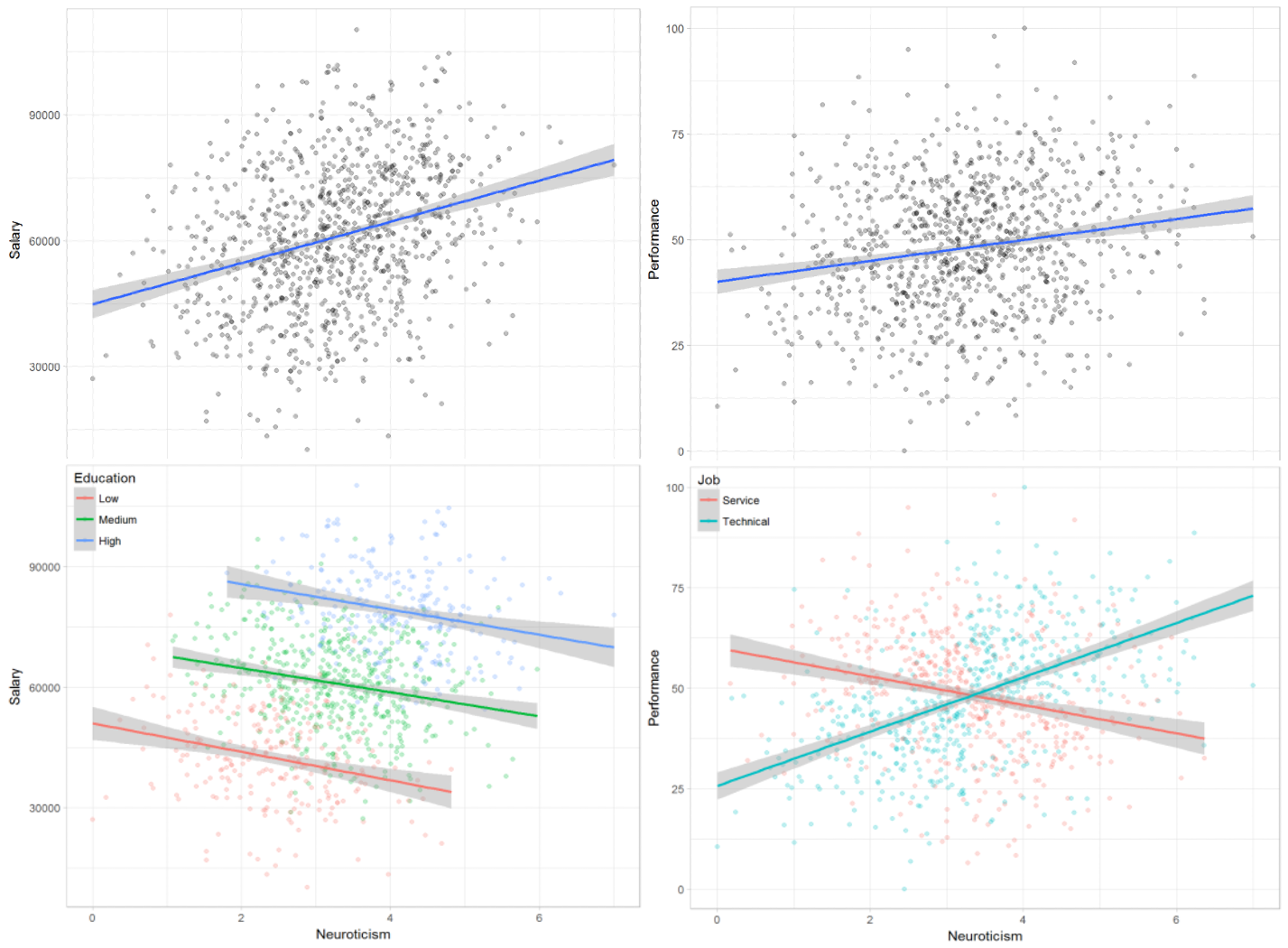
Simpson’s Paradox (2)
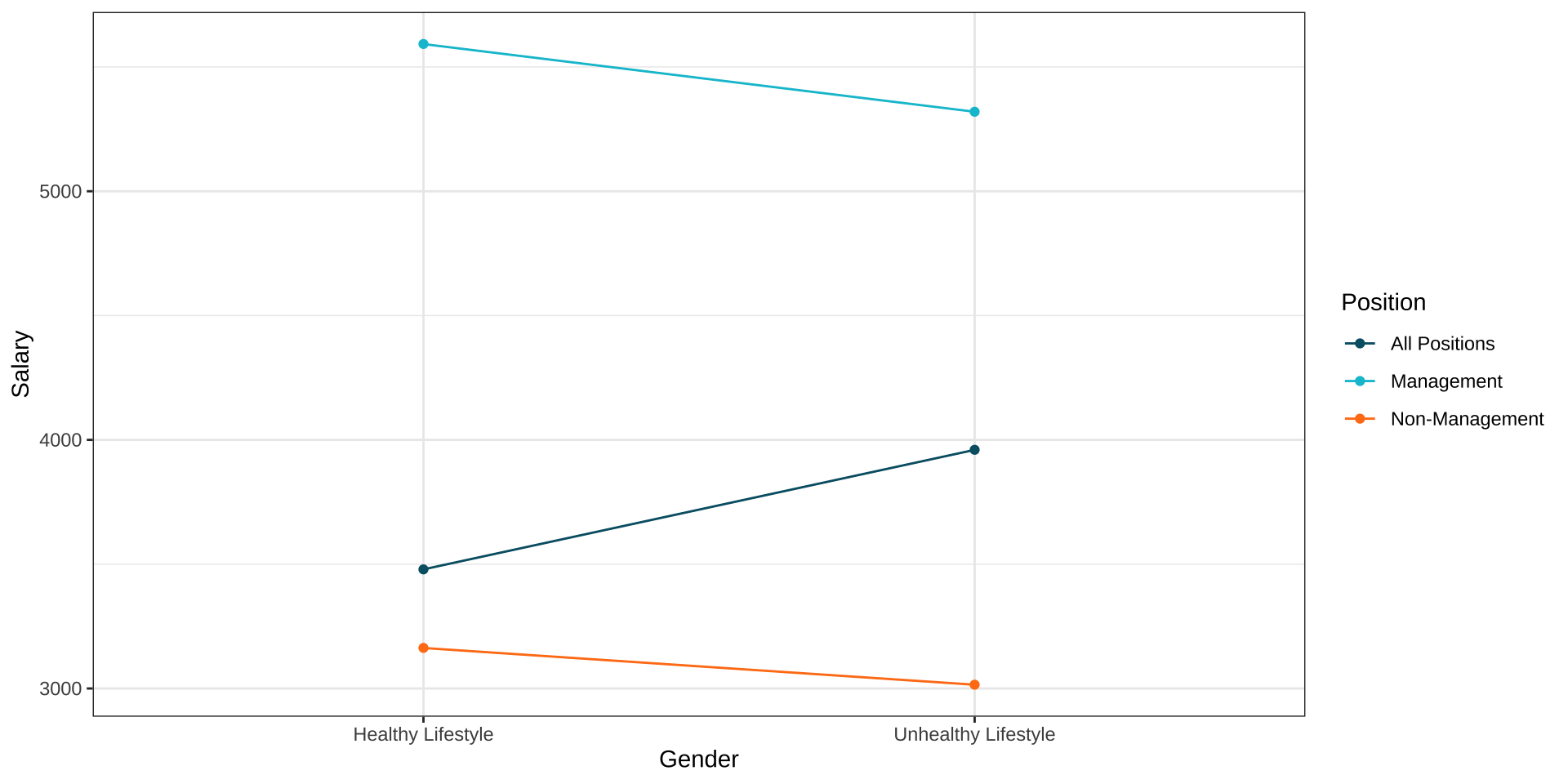
- Here, we would correctly infer that people with a healthy lifestyle earn more on average ($181.74).
Simpson’s Paradox (3)
- What is the difference between the two examples?
Show code
library(ggdag)
coord_dag <- list(
x = c(Gender = 0, Management = 1, Salary = 2),
y = c(Gender = 0, Management = 1, Salary = 0)
)
dag <- ggdag::dagify(Management ~ Gender,
Salary ~ Gender,
Salary ~ Management,
coords = coord_dag)
dag %>%
ggplot(aes(x = x, y = y, xend = xend, yend = yend)) +
geom_dag_point(colour = "grey") +
geom_dag_edges() +
geom_dag_text(colour = "black", size = 5) +
theme_dag(legend.position = "none")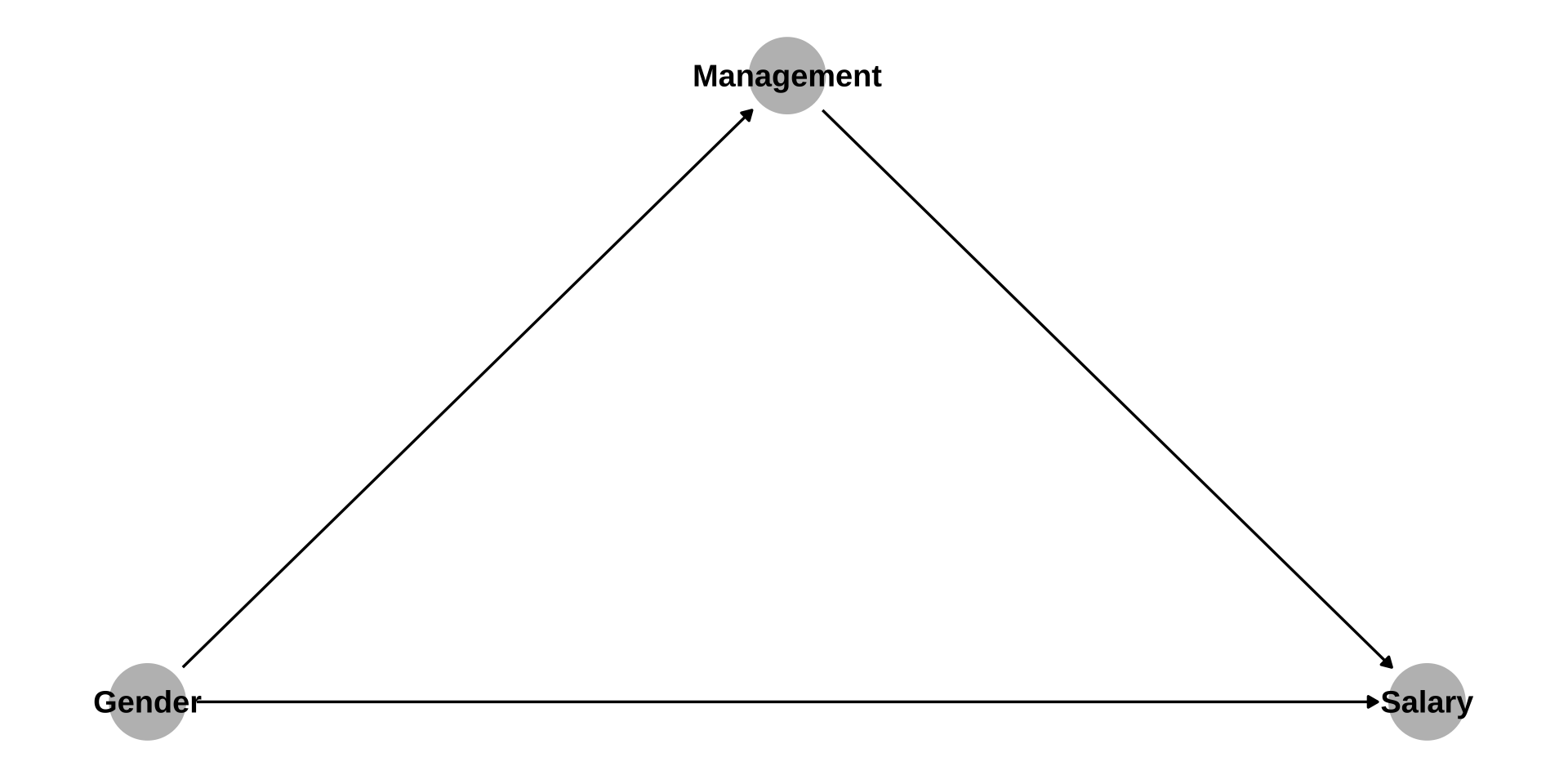
- Management as “mediator”
Show code
library(ggdag)
coord_dag <- list(
x = c(Lifestyle = 0, Management = 1, Salary = 2),
y = c(Lifestyle = 0, Management = 1, Salary = 0)
)
dag <- ggdag::dagify(Lifestyle ~ Management,
Salary ~ Lifestyle,
Salary ~ Management,
coords = coord_dag)
dag %>%
ggplot(aes(x = x, y = y, xend = xend, yend = yend)) +
geom_dag_point(colour = "grey") +
geom_dag_edges() +
geom_dag_text(colour = "black", size = 5) +
theme_dag(legend.position = "none")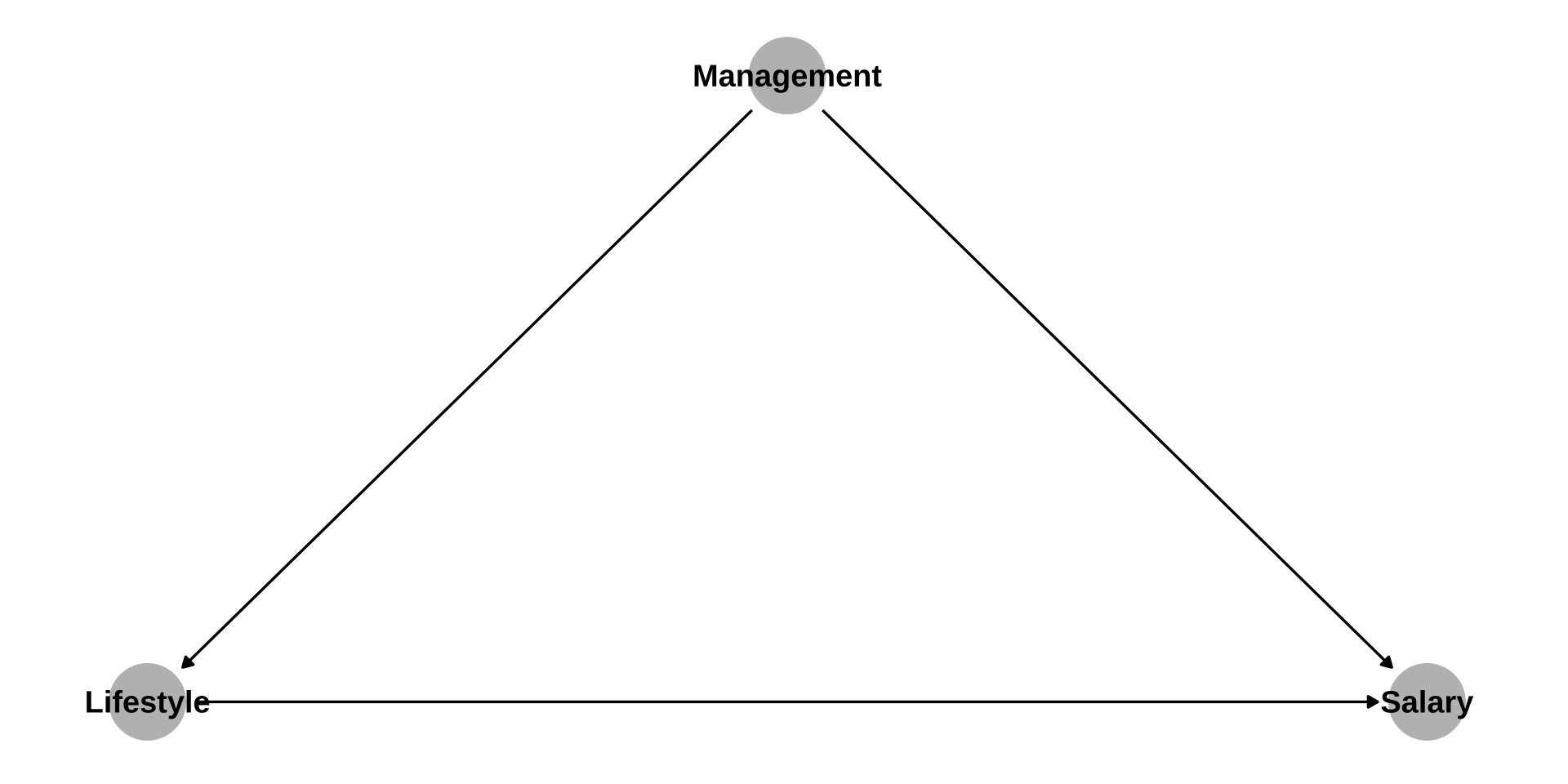
- Management as “confounder”
Simpson’s Paradox (5)
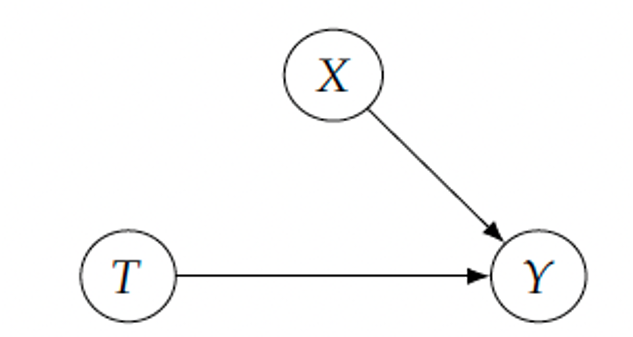
Assumptions in the PO Framework (2)
- We need to make further assumptions to make progress.
ATE Identification - Intuition
- Using assumptions 4 and 2, we obtain the following simplification:
- \(\mathbb{E}[Y_i(1)] - \mathbb{E}[Y_i(0)] = \mathbb{E}[Y_i(1)|T_i=1] - \mathbb{E}[Y_i(0)|T_i=0] = \mathbb{E}[Y_i|T_i=1] - \mathbb{E}[Y_i|T_i=0]\)
- This implies the ATE to be obtainable as associational difference:
| \(i\) | \(T_i\) | \(Y_i\) | \(Y_i(1)\) | \(Y_i(0)\) |
|---|---|---|---|---|
| 1 | 0 | 0 | ? | 0 |
| 4 | 0 | 0 | ? | 0 |
| 5 | 0 | 1 | ? | 1 |
| 2 | 1 | 1 | 1 | ? |
| 3 | 1 | 0 | 0 | ? |
| 6 | 1 | 1 | 1 | ? |
- We can then estimate \(\mathbb{E}[Y_i|T_i=1] = 0.66\) and \(\mathbb{E}[Y_i|T_i=0] = 0.33\) and use these values to replace the missing counterfactuals.
- ATE is now identifiable in the sense that it can be computed from a purely statistical quantity.
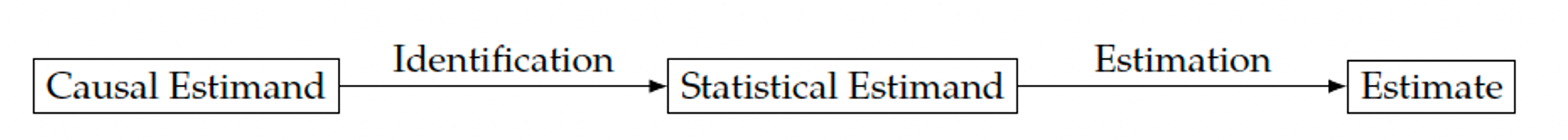
Assumptions in the PO Framework (3)
- Let’s make exchangeability more realistic, i.e. conditional on covariates, so that subgroups will be exchangable.
| Thank you for your attention! | |

|
|