(6) Heterogeneous Treatment Effects
Causal Data Science for Business Analytics
Monday, 24. June 2024
Group ATEs: Example based on DML
- Assess the effect of 401(k) program participation on net financial assets of 9,915 households in the US in 1991.
- First step (not shown): Estimate \(\hat{\tau}_{\text{ATE}}^{\text{AIPW}}\) using DoubleML.
# Get the indvidual ATEs (pseudo-outcomes)
data$ate_i <- dml_irm_forest[["psi_b"]] # get numerator of score function, which is equal to pseudo outcome
mean_ate = mean(data$ate_i) # mean of pseudo outcomes = ATE
library(estimatr) # for linear robust post estimation
summary(lm_robust(ate_i ~ hown, data = data))Estimates and significance testing of the effect of target variables
Estimate. Std. Error t value Pr(>|t|)
e401 8206 1106 7.421 1.16e-13 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Call:
lm_robust(formula = ate_i ~ hown, data = data)
Standard error type: HC2
Coefficients:
Estimate Std. Error t value Pr(>|t|) CI Lower CI Upper DF
(Intercept) 3477 711 4.890 1.025e-06 2083 4870 9913
hown 7445 1835 4.058 4.990e-05 3849 11041 9913
Multiple R-squared: 0.00106 , Adjusted R-squared: 0.0009588
F-statistic: 16.47 on 1 and 9913 DF, p-value: 4.99e-05
S-Learner and T-Learner: Example
- Assess the effect of 401(k) program participation on net financial assets of 9,915 households in the US in 1991.
- Examples without proper cross-fitting.
library(hdm) # for the data
library(grf) # generalized random forests, could also use mlr3
# Get data
data(pension)
# Outcome
Y = pension$net_tfa
# Treatment
T = pension$p401
# Create main effects matrix
X = model.matrix(~ 0 + age + db + educ + fsize + hown + inc + male + marr + pira + twoearn, data = pension)
# Implement the S-Learner
TX = cbind(T,X)
rf = regression_forest(TX,Y)
T0X = cbind(rep(0,length(Y)),X)
T1X = cbind(rep(1,length(Y)),X)
cate_sl = predict(rf,T1X)$predictions - predict(rf,T0X)$predictions
hist(cate_sl)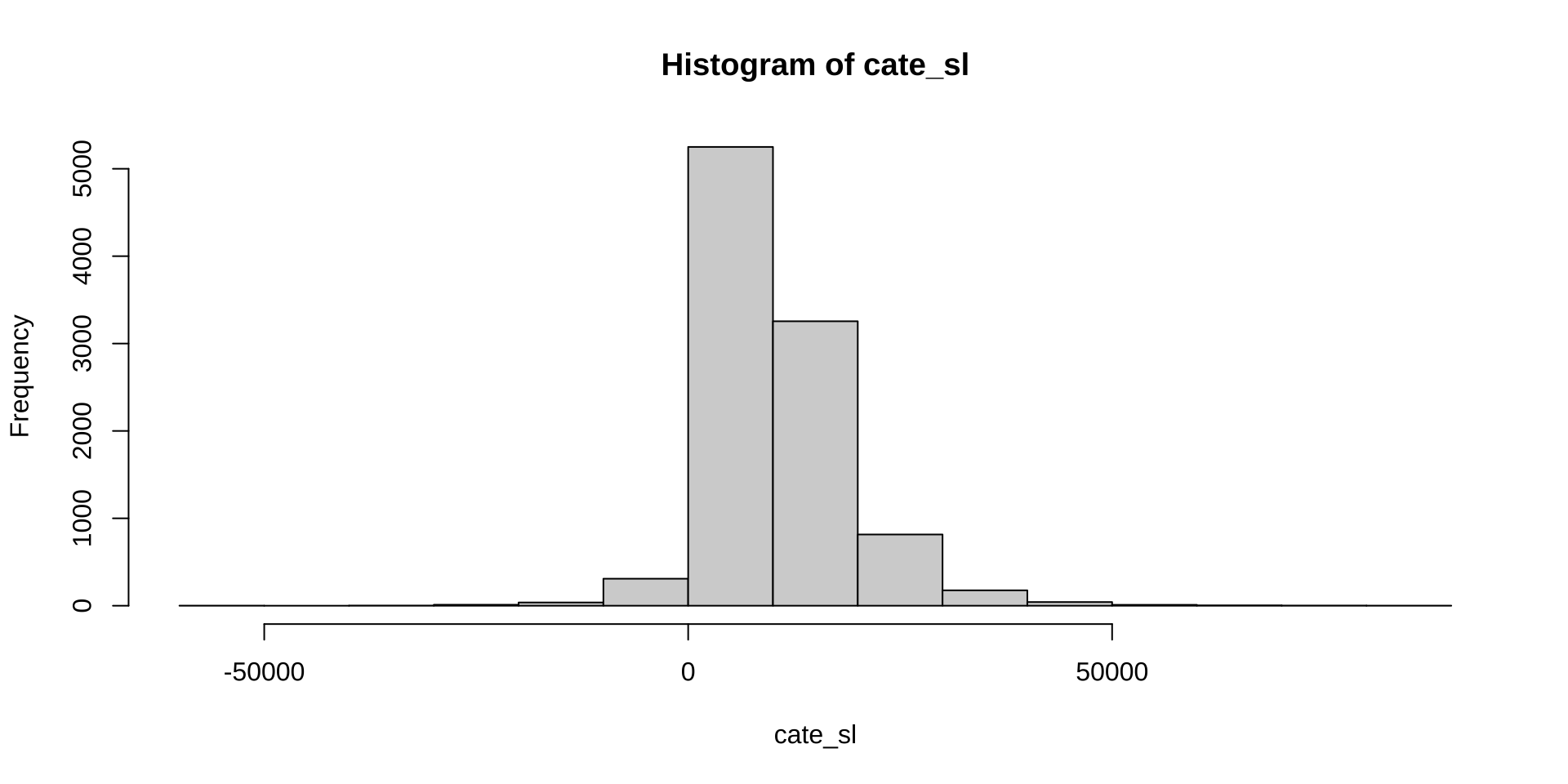
DR-learner: Example
- Assess the effect of 401(k) program participation on net financial assets of 9,915 households in the US in 1991.
library(hdm) # for the data
library(causalDML) # generalized random forests, could also use mlr3
# Get data
data(pension)
# Outcome
Y = pension$net_tfa
# Treatment
T = pension$p401
# Create main effects matrix
X = model.matrix(~ 0 + age + db + educ + fsize + hown + inc + male + marr + pira + twoearn, data = pension)
# Implement the DR-Learner
dr = dr_learner(Y,T,X,
ml_w = list(create_method("forest_grf")),
ml_y = list(create_method("forest_grf")),
ml_tau = list(create_method("forest_grf"))
)
# DR-learner distribution of B-A
hist(dr$cates[,1])
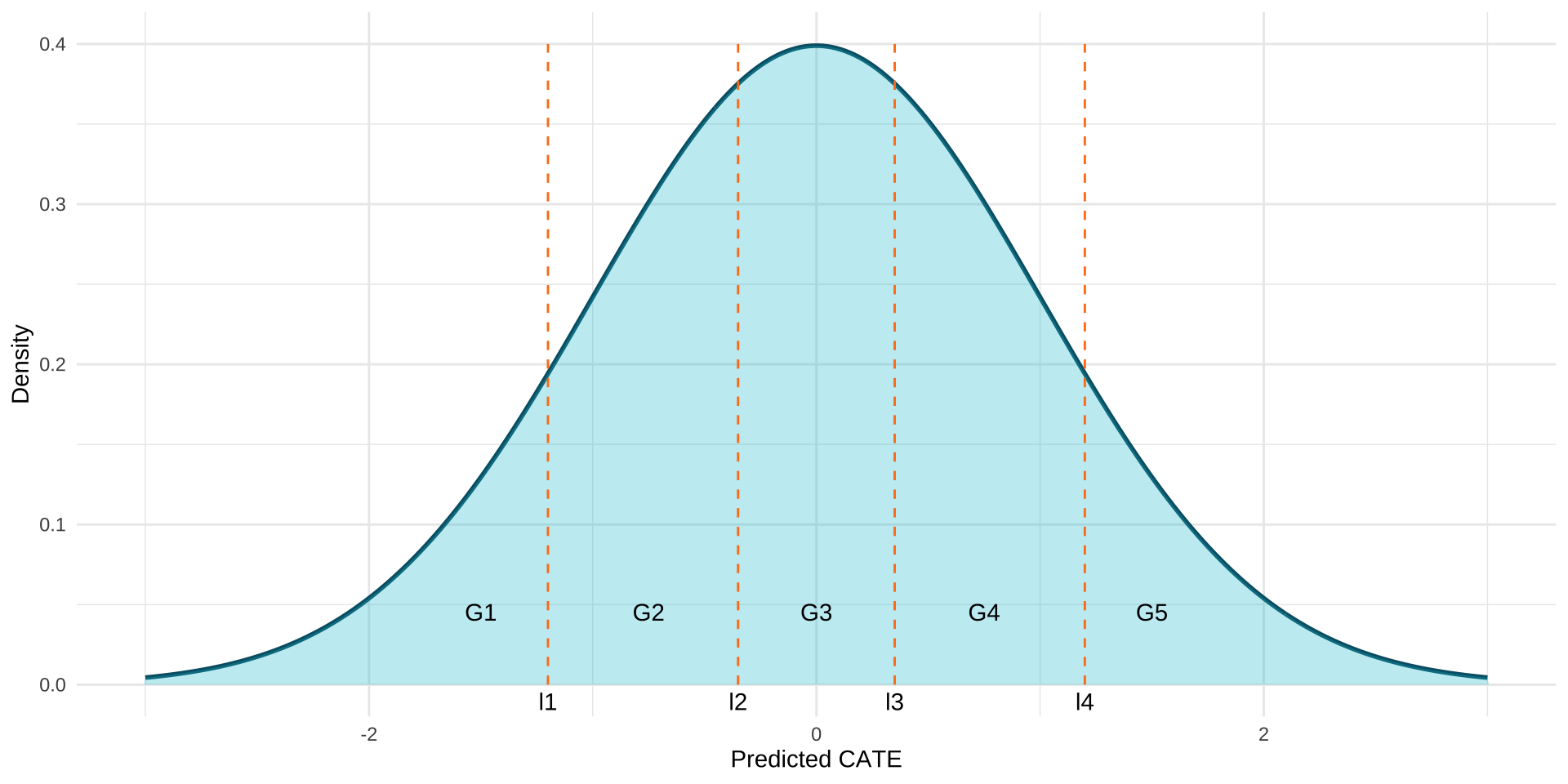
Sorted Group Average Treatment Effect (GATES)
Idea:- slice the distribution of \(\hat{\tau}(\mathbf{X_i})\) into \(K\) parts and compare the average treatment effect of individuals within each slice.
- if \(\hat{\tau}(\mathbf{X_i})\) is a good approximation of \(\tau(\mathbf{X_i})\), then we expect to observe the following monotonicity: \(\gamma_1 \leq \gamma_2 \leq \ldots \leq \gamma_K\).
Optimal Policy Learning: Example
- Assess the effect of 401(k) program participation on net financial assets of 9,915 households in the US in 1991.
- First step (not shown): Estimate \(\hat{\tau}_{\text{ATE}}^{\text{AIPW}}\) using DoubleML.
# Load required packages
library(mlr3)
library(mlr3learners)
library(tidyverse)
library(rpart.plot)
# Get and transform the indvidual ATEs (pseudo-outcomes)
data$ate_i <- dml_irm_forest[["psi_b"]] # get numerator of score function, which is equal to pseudo outcome
data$sign <- sign(data$ate_i) # get sign of pseudo outcomes
data$weights <- abs(data$ate_i) # get weights (absolute value of pseudo outcomes)
# Optimal Policy Learning with Classification Tree
data <- data[,c("sign", "weights", "age", "db", "educ", "fsize",
"hown", "inc", "marr", "pira", "twoearn")] # select columns
task <- as_task_classif(data, target = "sign") # task
task$set_col_roles("weights", roles = "weight") # define weights
lrnr <- lrn("classif.rpart") # learner decision tree
lrnr$train(task) # train
rpart.plot(lrnr$model, yesno = 2) # plot
# Classification Analysis
data$pi <- 2 * (as.numeric(lrnr$predict(task)$response) - 1.5) # Output takes values 1 and 2, therefore recode to -1/1
data_x <- data[, -c(1:2)] # remove sign and weights
CLAN = cbind(colMeans(data_x[pi == -1,]),colMeans(data_x[pi == 1,])) # calculate CLAN
colnames(CLAN) = c("No 401(k)","401(k)") # rename columns
round(CLAN,2) # print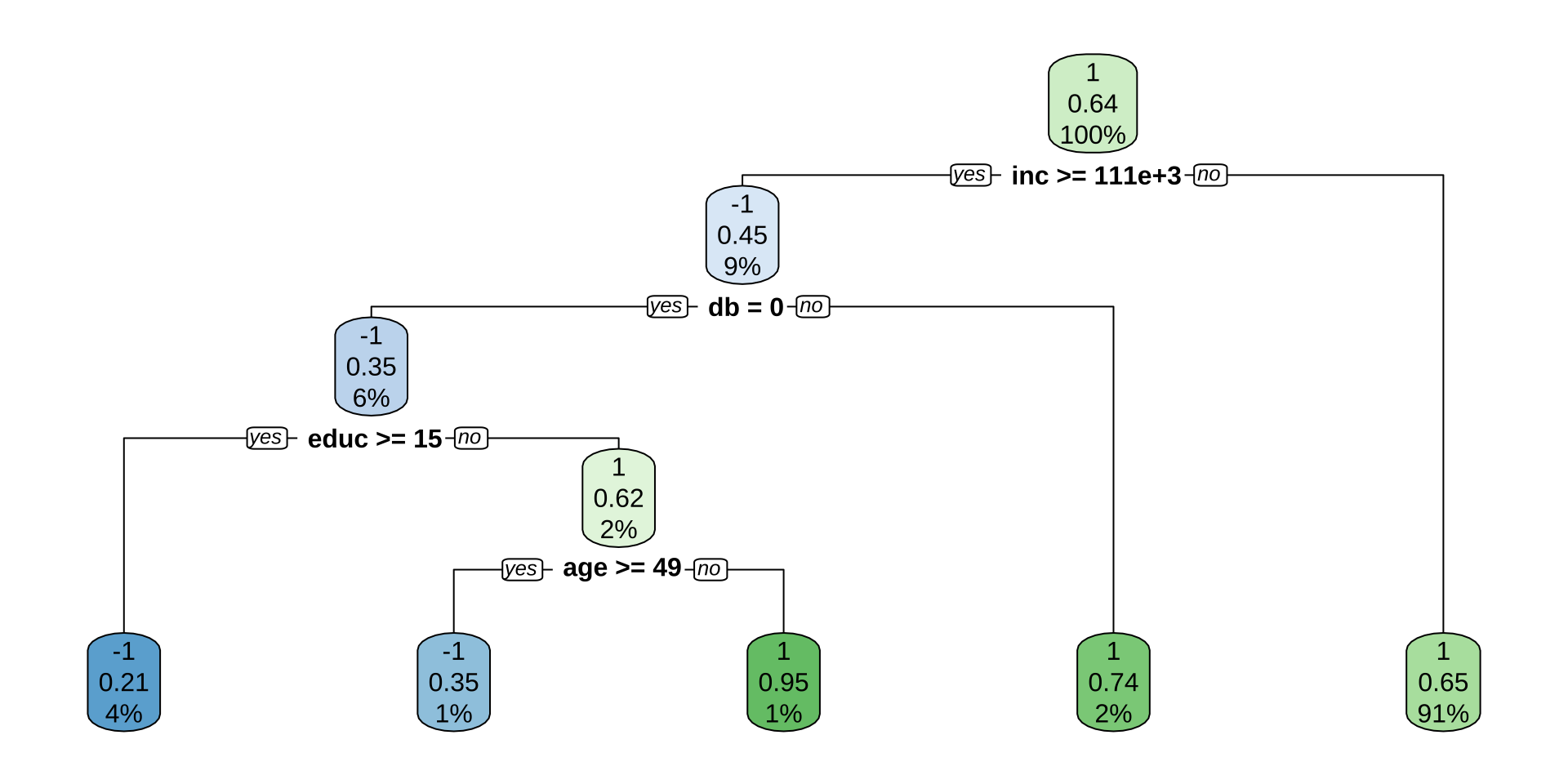
No 401(k) 401(k)
age 45.38 41.03
db 0.00 0.27
educ 16.02 13.19
fsize 2.95 2.87
hown 0.97 0.63
inc 138411.00 36532.74
marr 0.97 0.60
pira 0.72 0.24
twoearn 0.68 0.38
pi -1.00 1.00| Thank you for your attention! | |

|
|