(7) Unobserved Confounding and Instrumental Variables
Causal Data Science for Business Analytics
Monday, 24. June 2024
Motivation
Conditional Independence / Unconfoundedness: assumption is not testable.- “The Law of Decreasing Credibility: The credibility of inference decreases with the strength of the assumptions maintained.” (Manski, 2003)
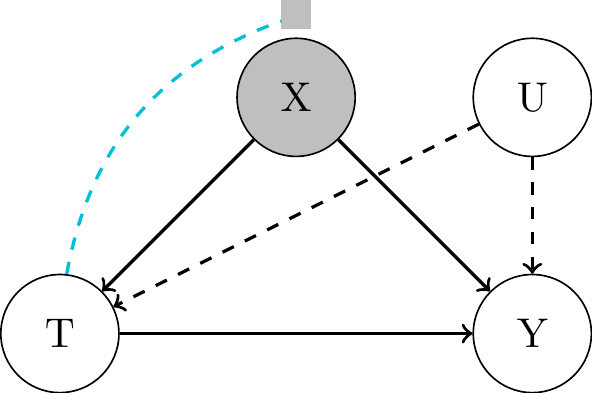
\[ \begin{align*} \tau_{\text{ATE}} &= \mathbb{E}[Y_i(1)] - \mathbb{E}[Y_i(0)] \\ &= \mathbb{E}_{\mathbf{X, U}}[\mathbb{E}[Y_i|T_i=1, \mathbf{X_i, U_i}] - \mathbb{E}[Y_i|T_i=0, \mathbf{X_i, U_i}]] \\ & \color{#FF7E15}{\stackrel{?}{\approx}} \mathbb{E}_{\mathbf{X}}[\mathbb{E}[Y_i|T_i=1, \mathbf{X_i}] - \mathbb{E}[Y_i|T_i=0, \mathbf{X_i}]] \end{align*} \]
- “Questionable” equality is required to hold for a
point estimateof the ATE. Partial Identificationis the method to estimate the ATE under weaker assumptions yielding aset estimate- an interval with upper and lower bounds.- Trade-off between assumptions and width of the interval.
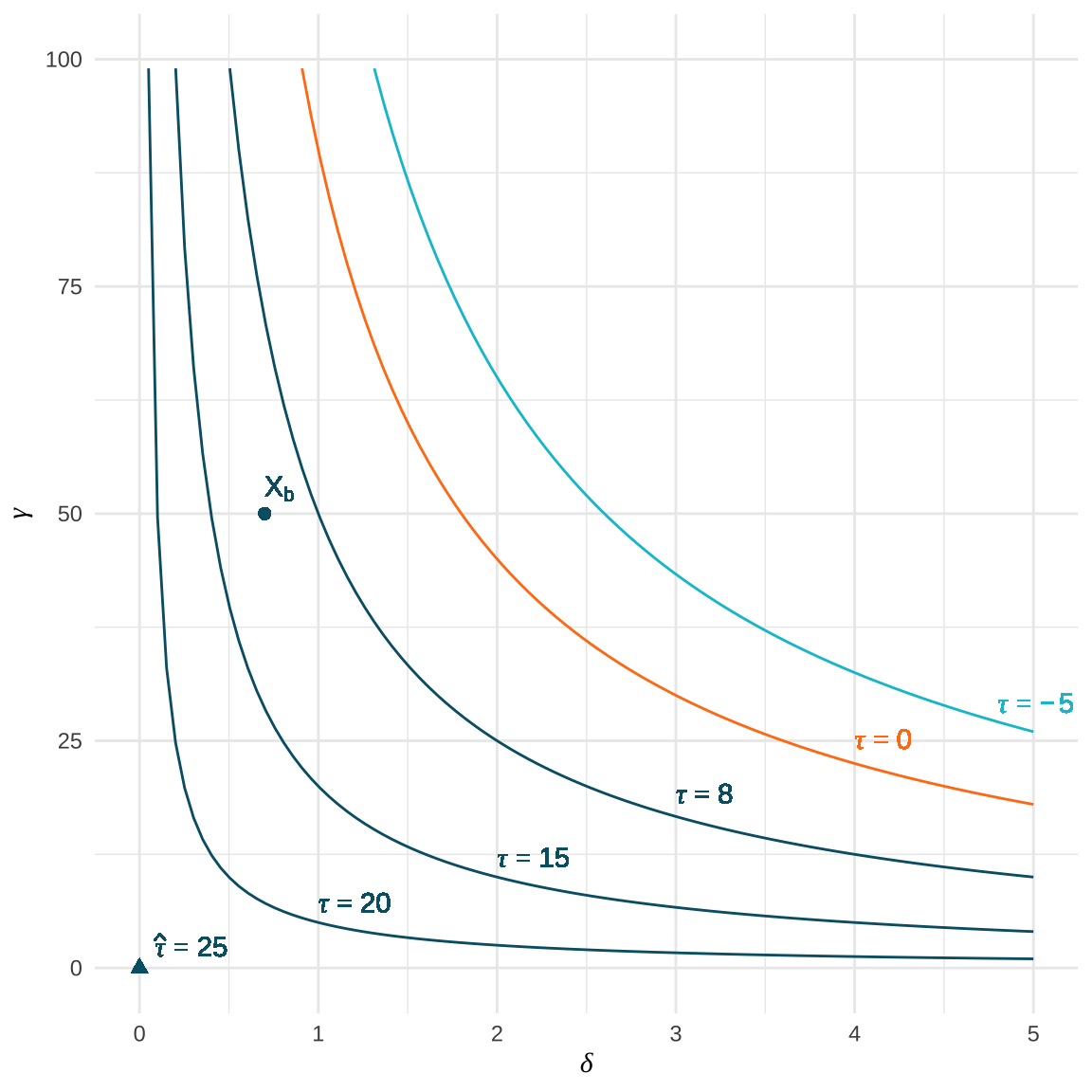
Ommitted Confounder Bias - Contour Plot
Hypothetical example: estimated treatment effect unadjusted for the unobserved confounder \(\tilde{\tau} = 25\).Levels of bias (contours) diminish the estimated \(\tilde{\tau}\) implying different levels of \(\tau\).
Benchmark covariates \(X_b\) for comparison.
Sensitivity Analysis: Example
- Assess the effect of 401(k) program participation on net financial assets of 9,915 households in the US in 1991.
library(hdm) # for the data
library(sensemakr) # load sensemakr package
data(pension) # Get data
# runs conditional outcome regression model
model <- lm(net_tfa ~ p401 + age + db + educ + fsize + hown + inc +
male + marr + pira + twoearn, data = pension)
# runs sensemakr for sensitivity analysis
sensitivity <- sensemakr(model = model, treatment = "p401",
benchmark_covariates = c("inc"), kd=1:3)
# plot
# plot(sensitivity)
# short description of results
sensitivitySensitivity Analysis to Unobserved Confounding
Model Formula: net_tfa ~ p401 + age + db + educ + fsize + hown + inc + male +
marr + pira + twoearn
Null hypothesis: q = 1 and reduce = TRUE
Unadjusted Estimates of ' p401 ':
Coef. estimate: 11590.38
Standard Error: 1345.253
t-value: 8.61577
Sensitivity Statistics:
Partial R2 of treatment with outcome: 0.00744
Robustness Value, q = 1 : 0.08291
Robustness Value, q = 1 alpha = 0.05 : 0.06468
For more information, check summary.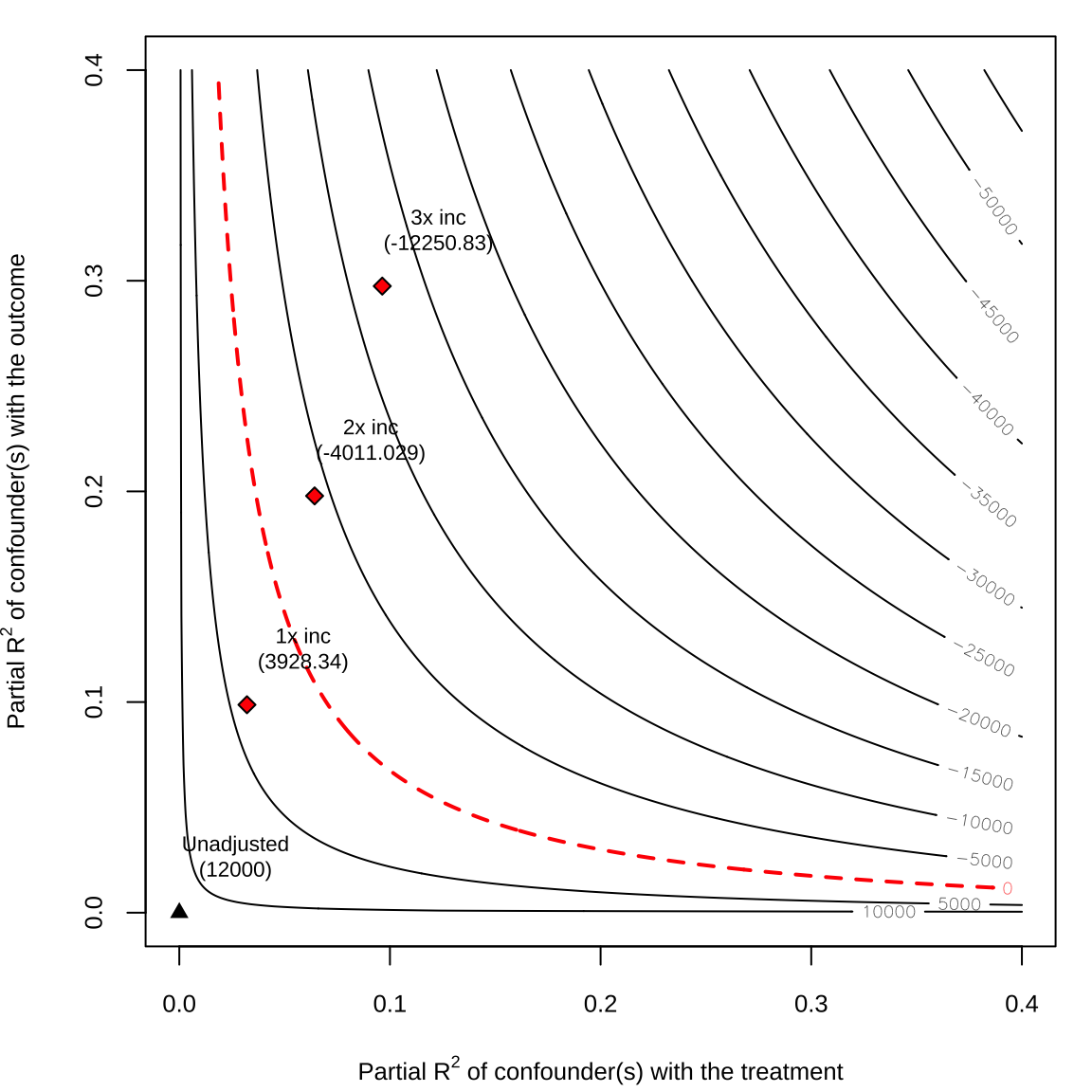
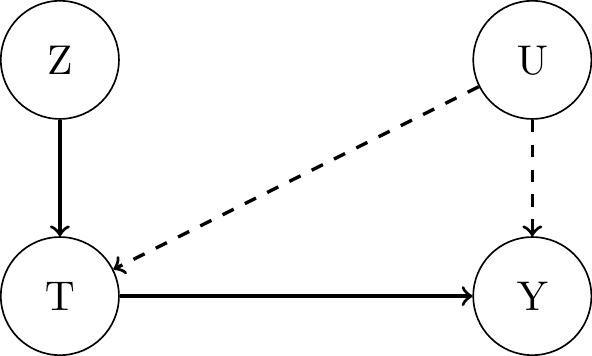
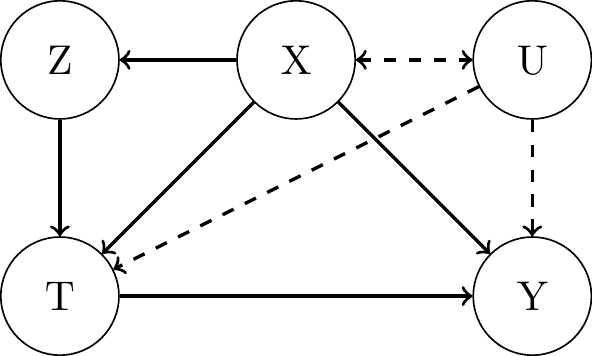
What is an Instrumental Variable?
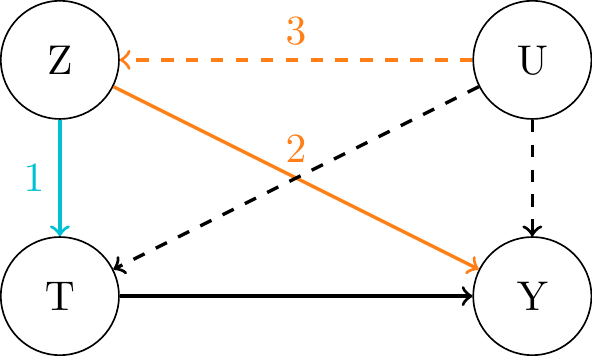
Assumptions:- Relevance: \(Z\) is significantly correlated with \(T\), i.e. \(Cov(Z, T) \neq 0\).
Path 1 must exist. - Exclusion Restriction: \(Z\) affects \(Y\) only through \(T\).
A direct path 2 must not exist. - Unconfoundedness (Exogeneity, Validity): \(Z\) is independent of \(U\), i.e. \(Cov(Z, \epsilon_Y) = 0\).
Conditioning on \(\mathbf{X}\) required in some contexts (will cover this later).
Path 3 must not exist.
- Relevance: \(Z\) is significantly correlated with \(T\), i.e. \(Cov(Z, T) \neq 0\).
- Even with these assumptions fulfilled, there is no nonparametric identification of the ATE.
- The backdoor path \(T \leftarrow U \rightarrow Y\) cannot be blocked.
- Two identification approaches:
Parametric assumption(i.e. linearity):- Identification of
homogeneous treatment effect.
- Identification of
- No parametric, but
monotonicity assumption:- Nonparametric identification of
Local Average Treatment Effect (LATE)instead of ATE.
- Nonparametric identification of
Two-Stage Least Squares Estimator (2SLS)
Stage: Linearly regress \(T_i\) on \(Z_i\) to estimate \(\mathbb{E}[T_i|Z_i]\). This gives the projection of \(T_i\) onto \(Z_i\): \(\hat{T}_i\).Stage: Linearly regress \(Y_i\) on \(\hat{T}_i\) to estimate \(\mathbb{E}[Y_i|\hat{T}_i]\). Obtain the estimate \(\hat{\tau}\) as the fitted coefficient of \(\hat{T}_i\).
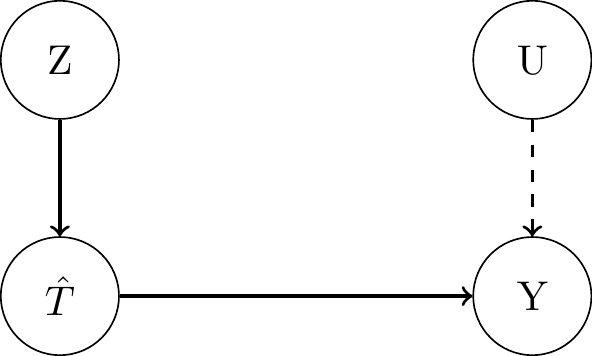
- Also works as an estimator in the binary setting.
Stratification of Data
- Define potential treatments conditional on \(Z_i\): \(T_i(0)\) if \(Z_i = 0\) and \(T_i(1)\) if \(Z_i = 1\).
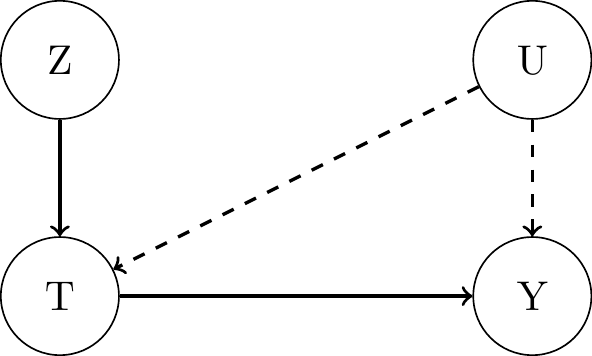
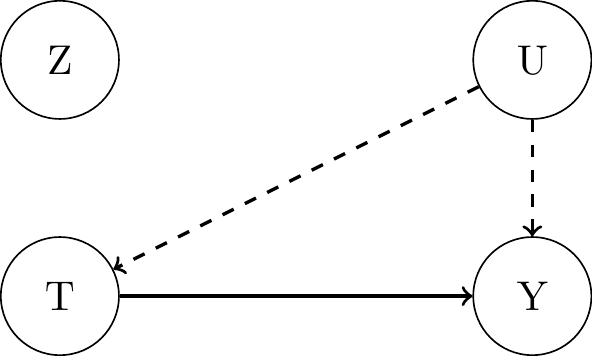
- Principal strata:
Compliersalways take the treatment that they’re encouraged to take: \(T_i(1) = 1\) and \(T_i(0) = 0\).Always-Takersalways take the treatment, regardless of encouragement: \(T_i(1) = 1\) and \(T_i(0) = 1\).Never-Takersnever take the treatment, regardless of encouragement: \(T_i(1) = 0\) and \(T_i(0) = 0\).Defiersalways take the opposite treatment that they’re encouraged to take: \(T_i(1) = 0\) and \(T_i(0) = 1\).
- Causal graph for compliers and defiers:
- Causal graph for always-takers and never-takers:
- But can’t identify what strata a given unit is in: e.g. \(Z_i = 0\) & \(T_i = 0\) could be compliers or never-takers; etc.
Motivation: Control for Covariates
- In many applications, it may not be credible that IV assumptions like random assignment hold unconditionally, i.e. without controlling for observed covariates.
- Natural experiments vs. purely randomized encouragement design.
- Problematic if covariates are confounders between instrument and outcome.
- E.g. geographic proximity to college as IV when assessing the effect of eductaion (treatment) on earnings (outcome). Pros & cons of this IV?
- 2SLS can be extended, but the linear specification for covariates has to be correct.
| Thank you for your attention! | |

|
|