(9) Synthetic Controls
Causal Data Science for Business Analytics
Monday, 1. July 2024
Example
- Assess the effect of the terrorist conflict in the Basque region on GDP per capita based on a synthetic control created from other Spanish regions.
library(Synth)
library(SCtools)
data(basque)
dataprep.out <- dataprep(
foo = basque,
predictors = c("school.illit", "school.prim", "school.med", # define covariates: school degrees and investment as share of GDP
"school.high", "school.post.high", "invest"),
time.predictors.prior = 1964:1969, # define pre treatment period to average covariates over
special.predictors = list( # addtional predictors with special periods to average over
list("gdpcap", 1960:1969 ,"mean"), # pre-treatment outcomes - GDP
list("sec.agriculture", seq(1961, 1969, 2), "mean"), # production in different sectors
list("sec.energy", seq(1961, 1969, 2), "mean"),
list("sec.industry", seq(1961, 1969, 2), "mean"),
list("sec.construction", seq(1961, 1969, 2), "mean"),
list("sec.services.venta", seq(1961, 1969, 2), "mean"),
list("sec.services.nonventa", seq(1961, 1969, 2), "mean"),
list("popdens", 1969, "mean")), # population density
dependent = "gdpcap",
unit.variable = "regionno",
unit.names.variable = "regionname",
time.variable = "year",
treatment.identifier = 17, # treated unit
controls.identifier = c(2:16, 18), # control units
time.optimize.ssr = 1960:1969, # periods to optimize over
time.plot = 1955:1997)
synth.out = synth(dataprep.out)
path.plot(dataprep.res = dataprep.out, synth.res = synth.out,Xlab="Year",Ylab="GDP Per Capita")
abline(v=1970,lty=2,col="#005e73")
# average treatment effect on the treated over post-treatment period
mean(dataprep.out$Y1plot[16:43] - (dataprep.out$Y0plot[16:43,] %*% synth.out$solution.w))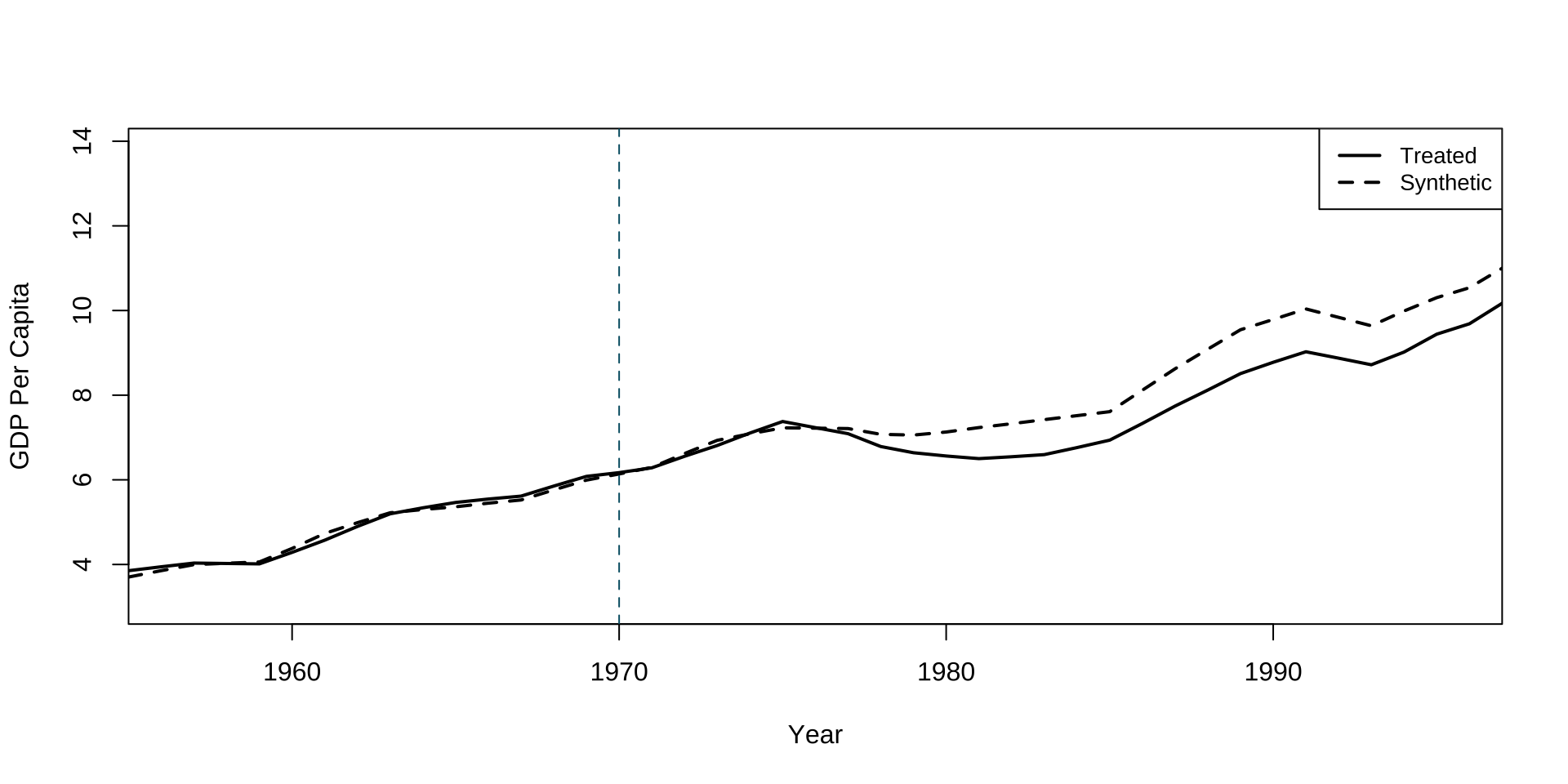
[1] -0.5799225Example: Inference
library(Synth)
library(SCtools)
# generate placebo tests
placebo <- generate.placebos(dataprep.out = dataprep.out,synth.out = synth.out, strategy = "multisession")
# p-value: how extreme the treated unit’s ratio is in comparison with that of placebos.
# but filter out control units with extreme MSPE ratios
# resulting from poor fit in the pre-treatment period
mspe_test(placebo, discard.extreme = TRUE, mspe.limit = 5)
# plot placebo tests, but filter out control units with extreme MSPE ratios
# resulting from poor fit in the pre-treatment period
plot_placebos(placebo, discard.extreme = TRUE, mspe.limit = 5)$p.val
[1] 0.8571429
$test
MSPE.ratios unit
1 399.28801 Andalucia
2 76.85500 Aragon
3 7767.20471 Principado De Asturias
4 55.67757 Canarias
5 2564.77781 Cantabria
6 470.57144 Castilla Y Leon
7 22.92823 Castilla-La Mancha
8 32.11487 Cataluna
9 114.23552 Comunidad Valenciana
10 90.72002 Galicia
11 130.86336 Murcia (Region de)
12 167.21979 Navarra (Comunidad Foral De)
13 156.15636 Rioja (La)
14 55.64514 Basque Country (Pais Vasco)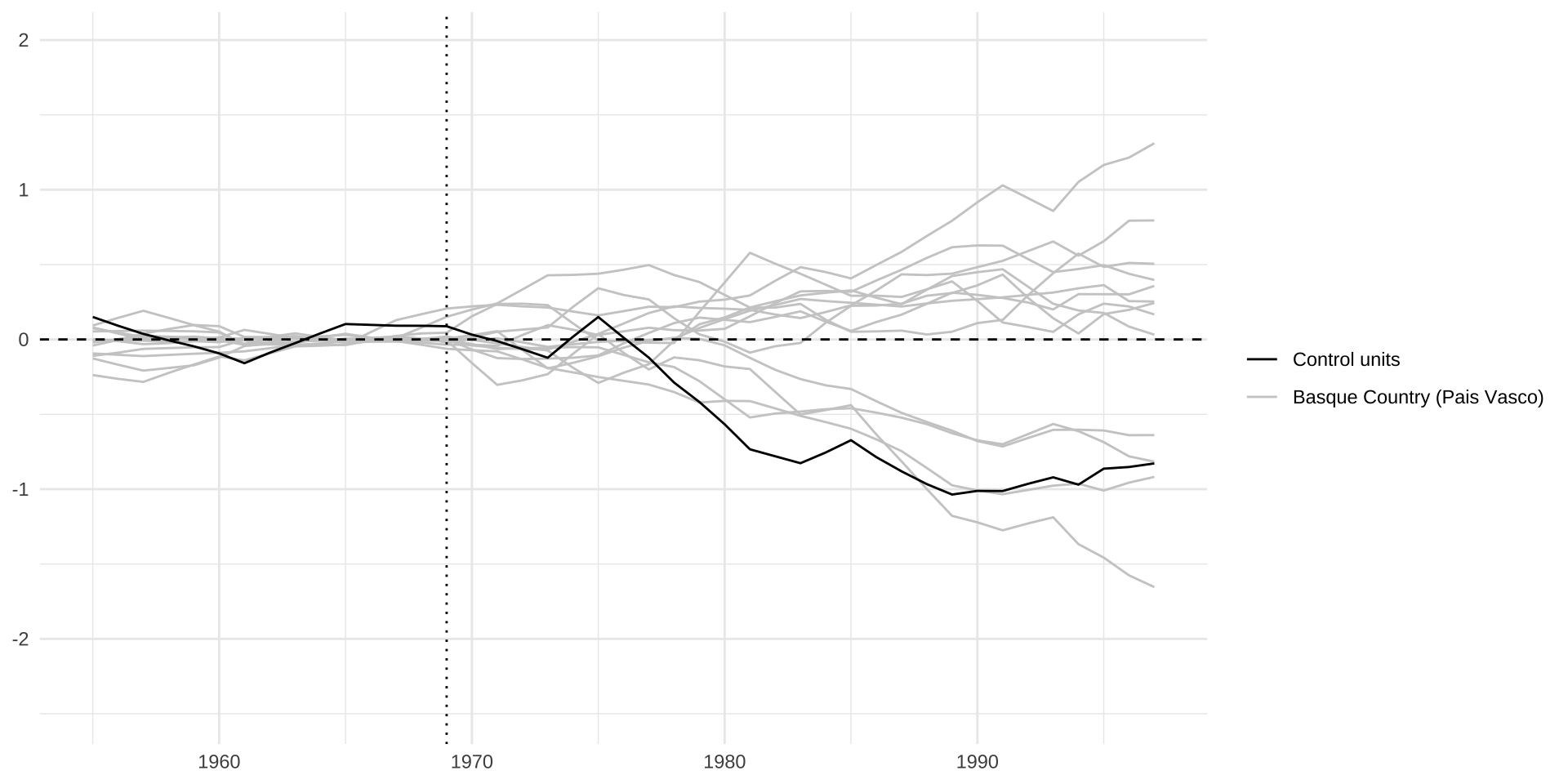
Extrapolation and Regularization
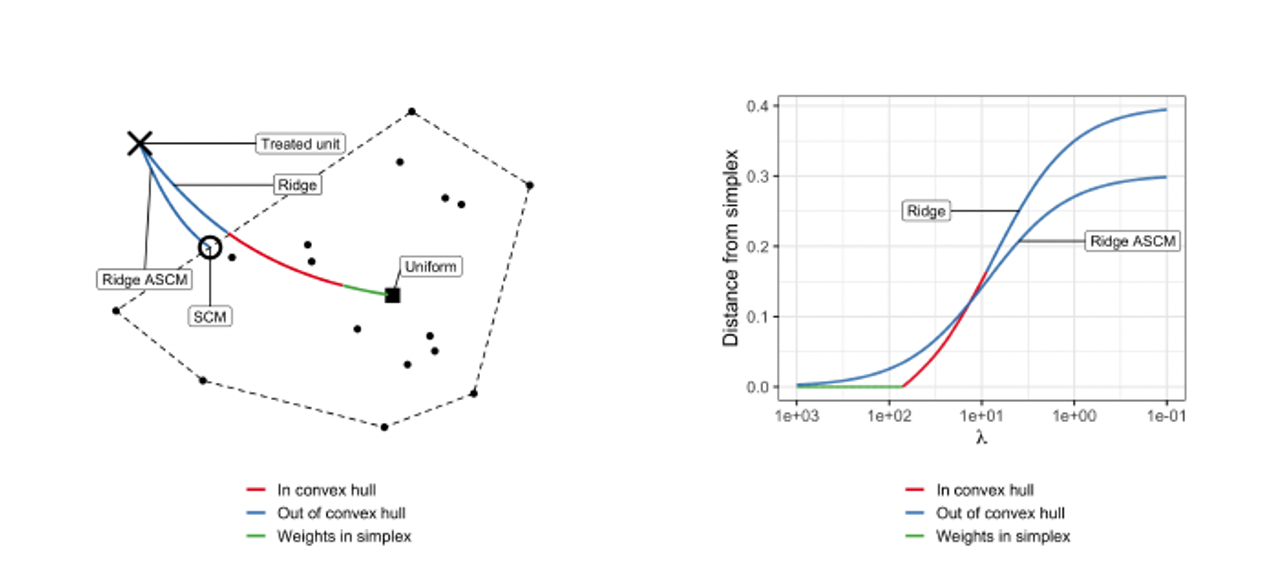
Augmented Synthetic Controls: Example
- Assess the impact of personal income tax cuts in Kansas on gross state product (GSP) per capita.
library(augsynth)
data(kansas)
attach(kansas)
# outcome ~ treatment | auxillary covariates
results <- augsynth(lngdpcapita ~ treated | lngdpcapita + log(revstatecapita) +
log(revlocalcapita) + log(avgwklywagecapita) +
estabscapita + emplvlcapita,
unit = fips,
time = year_qtr,
data = kansas,
progfunc = "Ridge",# function to use to impute control outcomes
scm = T) # whether to use the SCM
summary(results) # summarize the results
plot(results) # plot the results
# percentage change from the logged treatment effect
(exp(-0.0609)-1)*100 = -5.9%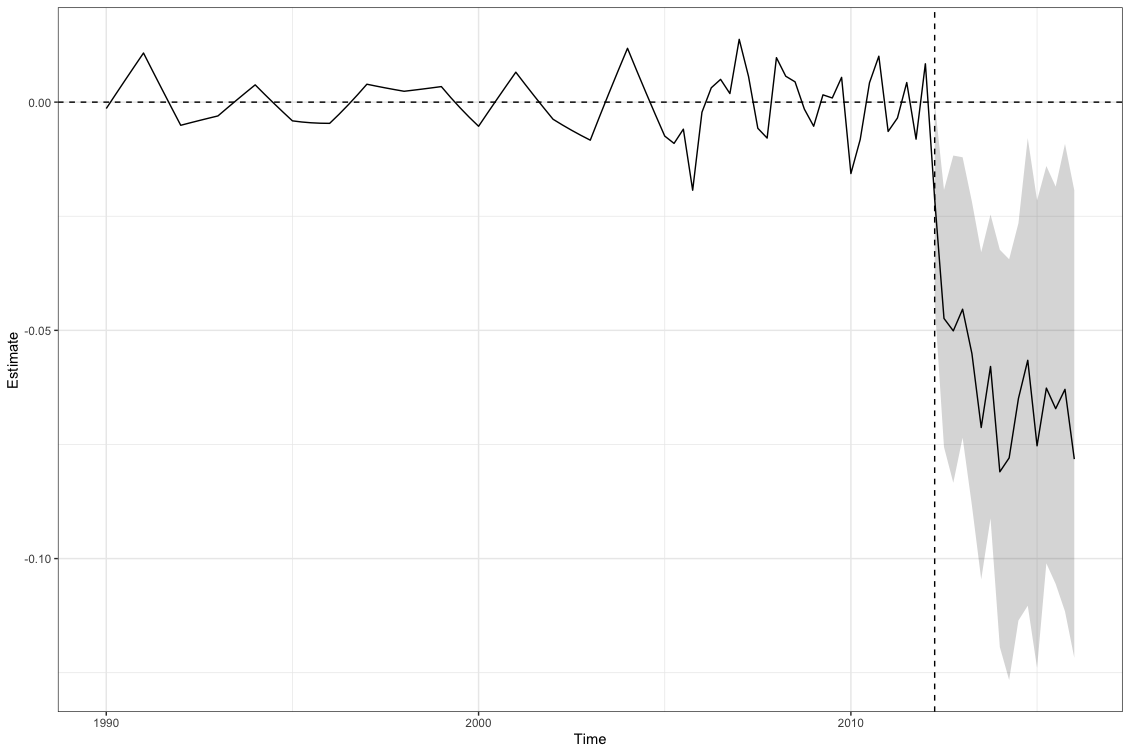
Call:
single_augsynth(form = form, unit = !!enquo(unit), time = !!enquo(time),
t_int = t_int, data = data, progfunc = "Ridge", scm = ..2)
Average ATT Estimate (p Value for Joint Null): -0.0609 ( 0.14 )
L2 Imbalance: 0.054
Percent improvement from uniform weights: 86.6%
Covariate L2 Imbalance: 0.005
Percent improvement from uniform weights: 97.7%
Avg Estimated Bias: 0.027
Inference type: Conformal inference
Time Estimate 95% CI Lower Bound 95% CI Upper Bound p Value
2012.25 -0.021 -0.044 0.002 0.058
2012.50 -0.047 -0.081 -0.019 0.039
2012.75 -0.050 -0.083 -0.012 0.031
2013.00 -0.045 -0.074 -0.022 0.034
2013.25 -0.055 -0.083 -0.022 0.025
2013.50 -0.071 -0.110 -0.033 0.025
2013.75 -0.058 -0.091 -0.025 0.024
2014.00 -0.081 -0.119 -0.037 0.027
2014.25 -0.078 -0.116 -0.024 0.013
2014.50 -0.065 -0.114 -0.006 0.040
2014.75 -0.057 -0.110 0.000 0.050
2015.00 -0.075 -0.124 -0.022 0.037
2015.25 -0.063 -0.106 -0.014 0.022
2015.50 -0.067 -0.106 -0.019 0.025
2015.75 -0.063 -0.101 -0.009 0.028
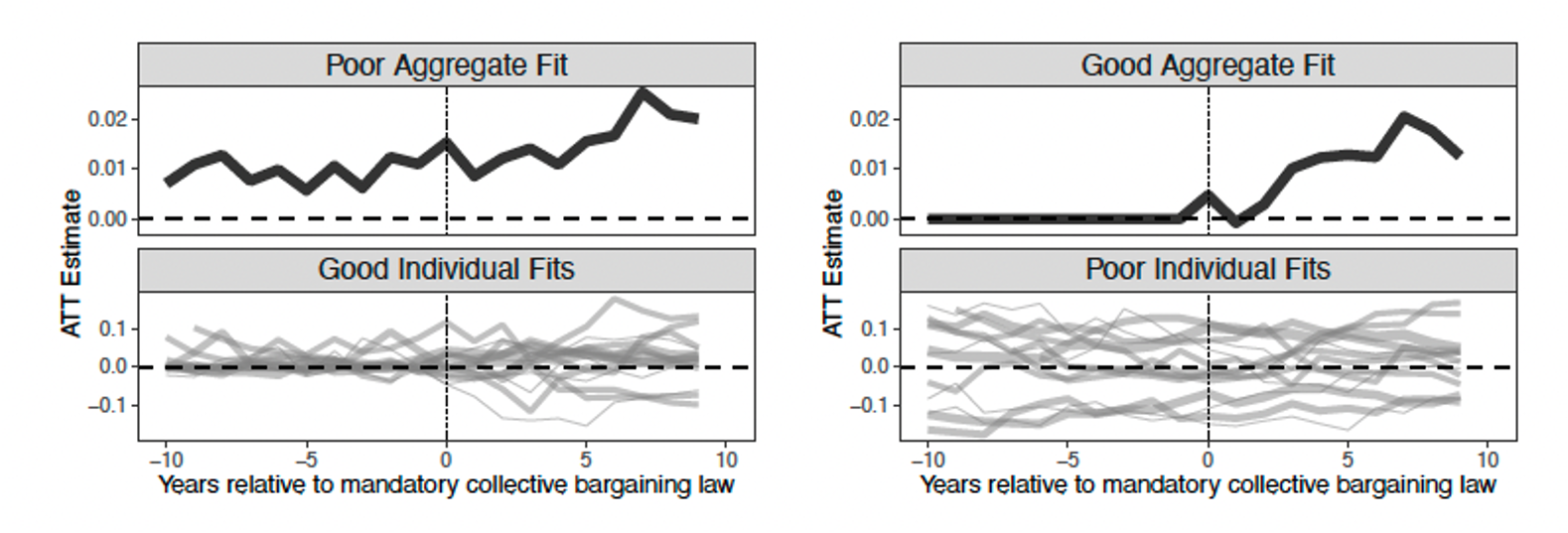
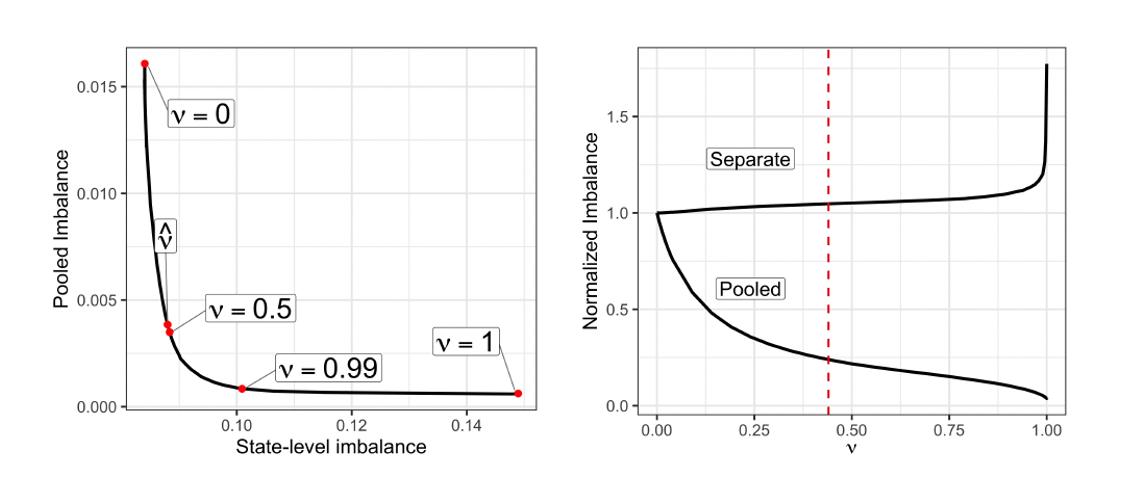
2016.00 -0.078 -0.127 -0.030 0.019Optimization Problem: Trade-off
Optimization Problem: Role of \(\nu\)
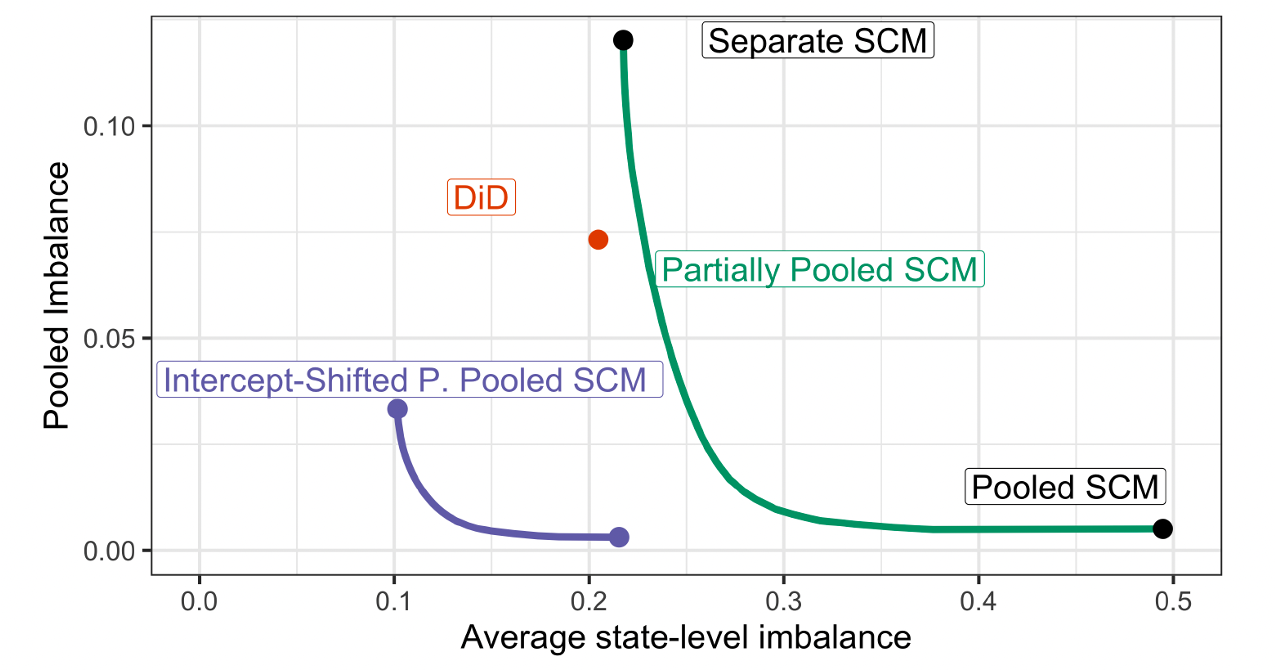
Optimization Problem: Intercept-Shifts
- Intercept-Shifted Partially-pooled SCM improves the optimization frontier.
- With uniform weights, “stacked” (two-period, two-groups) Difference-in-Differences is obtained.
| Thank you for your attention! | |

|
|